DNS Defined - Domain Name System
What Is the Domain Name System?
The Domain Name System (DNS) is the host addressing system of the Internet. DNS provides the address and naming conventions for all networks and lets Internet users obtain information about other networks and hosts by accessing a distributed database.
It became clear in the mid-1970s that the volume of new hosts on the Internet demanded that there be a host-name-to-address mapping scheme. ARPANET (a wide-area network created in 1969 that provided the basis for the Internet's protocol suite) had maintained a HOSTS.TXT file that had to be copied and maintained on each host in the network. This method needed an overhaul. A new method emerged, as outlined in Internet Requests for Comments (RFC) 882 and 883 on DNS. These RFCs appeared in 1984 and were subsequently updated by RFC 1034 and RFC 1035, which are the current standards.
DNS’s distributed database mechanism allows local control of Internet host names in a networked area (the local domain) while providing information about these hosts to other domains. Multiple levels of domain name servers replicate and cache the information. Meanwhile, the host name and address information is structured hierarchically, a robust arrangement that increases performance over other “flat” namespace systems.
Using DNS, a client host can ask a number of participating domain name servers about a remote host. If a name server doesn't know about the remote host directly, it refers the host name server to another server that can provide the information, and so on down the line.
DNS services, such as TCPware's Domain Name Services, provide DNS to upper-layer protocols, such as FTP and SMTP, when they need host information. Figure 1 is an example of how DNS works.
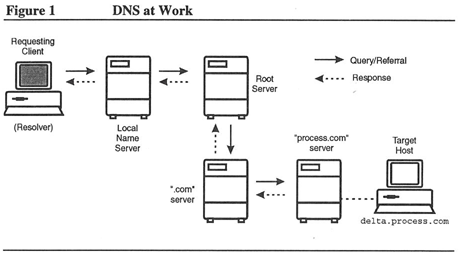
Do I Need DNS?
Whether you use DNS depends upon your company’s needs, size, and future plans. Here are some questions to ask when making your decision.
- Are you connected to the Internet? If you are, you need DNS. Almost all TCP/IP applications use DNS to target addresses and get host information. These include e-mail, remote terminal access (RLOGIN and TELNET), file transferring and sharing (FTP and NFS), the X Window System, and information services such as NSLOOKUP and the World Wide Web.
- Are you using e-mail? Chances are that if you have an e-mail facility running, whether it be SMTP or UUCP, you already have a domain set up. You're most likely already using user@domain-style mail addressing.
- Do you have your own heterogeneous internet? If you already have a TCP/IP-based “network of networks,” you probably need DNS.
- Do you have a simple LAN or site network? If you do, you might not need DNS. However, consider DNS for the future, especially if you plan to expand to a “corporate” network, or the Internet itself.
If you plan carefully, the benefits of DNS can quickly outweigh the cost of managing DNS.
What Is a Domain?
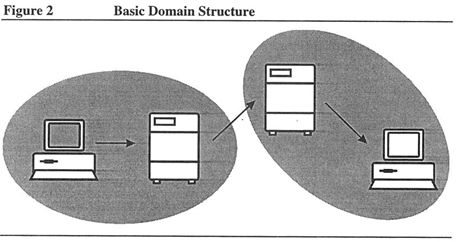
Abstractly speaking, a domain is a subset of the internet from which you and other hosts access a domain name server. Consider Figure 1 above: Remove the unused name servers, circle the domains, and you get Figure 2. To be realistic, add many more hosts and at least another name server to each domain. Strictly speaking, a domain is a subtree of the domain namespace — as described in the next section.
Domain Namespace
DNS evolved from a need to keep track of host names and addresses throughout the Internet. Because of the Internet's rapid growth, maintaining a single host table in a central location became impractical, for two reasons:
- The administrative tasks became prohibitive.
- Excessive network resources were required for distribution.
DNS solves these problems because it provides a hierarchy for host name administration. It also accurately distributes host name and address information throughout the Internet and does so only on an as-needed basis.
Internet hosts’ namespace consists of hierarchically arranged domains. The hierarchy resembles an inverted tree, much like a file system. Domain are like directory structures in a filesystem. At the top is the root domain (root directory) with branches to one or more domains and subdomains (directories and subdirectories), as in Figure 3.
The difference is the way you “read” domain names as opposed to a filesystem name. Read the UNIX filesystem in Figure 3 from top to bottom, so that you get /user/local/bin. Read the DNS namespace from bottom to top; HOMER.PROCESS.COM. is the way it reads. In DNS, a dot separates the domains, much like a slash separates directories in UNIX, with a final dot signifying the “root” domain. The dot (.) after COM in the name represents the top-level domain.
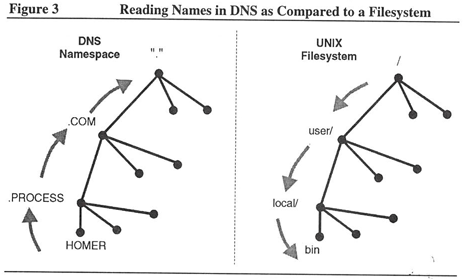
Internet addresses are also in "decimal" notation, but again in the opposite order from domain names. With an internet address such as 192.42.95.90, the rightmost field (90) identifies the host. With a domain name (HOMER.PROCESS.COM.), the leftmost field (HOMER) identifies the host.
There are a number of top-level domains that divide the namespace into general categories. These domains retain authority over the lower-level ones. This decentralizes namespace administration so that administrative issues in one domain don't involve those of another. The current top level domains are listed in Table 1.
| Domain Name | Meaning | Example |
|---|---|---|
| COM | Commercial organizations | process.com |
| EDU | Educational institutions | berkeiey.edu |
| GOV | Government organizations | nasa.gov |
| MIL | Military organizations | army.mil |
| NET | Network support centers | near.net |
| ORG | Other organizations | eff.org |
| ARPA | ARPANET domain | in-addr.arpa |
| INT | International organizations | nato.int |
| nn | ISO 3166 Country abbreviations | au (for Australia) |
Each top-level domain contains subdomains. The top-level domain delegates authority to its subdomains to administer their parts of the namespace. These subdomains can further delegate authority to lower-level subdomains, and so on. The bottom subdomain is the leaf domain, generally the host level.
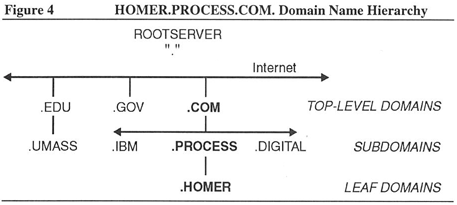
Figure 4 illustrates the HOMER.PROCESS.COM. domain in a slightly different way than Figure 3 on the previous page. Figure 4 shows the domain's relationship to other top-level domains and their subdomains. In the example, the COM domain includes the IBM, PROCESS, and DIGITAL subdomains. HOMER is a leaf domain under PROCESS. The EDU top-level domain includes the UMASS subdomain. The subdomains of GOV are not shown in the figure, although there are many of them.
Delegation, Zones, and Name Servers
One aspect of the distributed, decentralized nature of DNS is the concept of delegation. Not all domain namespaces are administered only from the “top.” For example, the .COM top-level domain cannot realistically administer its vast number of subdomains and hosts on its own. Domains generally delegate some or all authority to their subdomains. For example, .COM can delegate the administration of HOMER to the subdomain PROCESS, which includes HOMER.
To further explain this, see Figure 5 as an example of zones. If SALES were a subdomain instead of a host, PROCESS could further delegate authority for SALES and its hosts to SALES. However, PROCESS might have other subdomains to which it does not want to delegate administration.
Let's clarify this by expanding the SALES.PROCESS.COM namespace to include other subdomains. In the example, PROCESS delegates authority for SALES's subdomain to SALES, whereas PROCESS keeps the authority for the PLATO and CATO subdomains to itself.
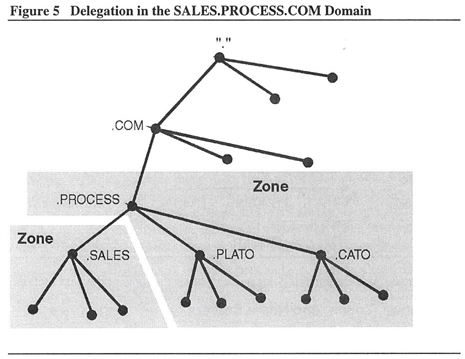
These areas are called zones. Each of these zones includes one or more domain name servers that maintain the domain name database for that zone. As you can see, name servers load zone data instead of data for the entire domain because part of the domain might have been delegated elsewhere.
Types of Name Servers
DNS defines five types of name servers: root, primary master, secondary master, caching, and slave.
Root Name Server
A root name server is the ultimate Internet authority. Although each root server can’t tell you the name and internet address of each host on the Internet, it can tell you which name server to query for that information.
For example, if the root name server A.ROOT-SERVER.NET doesn't have the internet address for DAISY.PROCESS.COM, it directs the query for the address to the COM name server. COM, in turn, directs the query to PROCESS.COM, and so on in the hierarchy of domain names.
Only the Network Information Center (NIC) has the authority to create root name servers. Table 2 lists the domain names of the current root name servers along with their Internet address. (Note that this list does change occasionally.)
| Domain Name | Internet Addresses |
|---|---|
| NS.INTERNIC.NET | 198.41.0.4 |
| NS.NIC.DDN.MIL | 192.112.36.4 |
| KAVA.NISC.SRI.COM | 192.33.33.24 |
| C.NYSER.NET | 192.33.4.12 |
| TERP.KUMD.EDU | 128.8.10.90 |
| NS.NASA.GOV | 128.102.16.10 192.52.195.10 |
| AOS.BRL.MIL | 192.5.25.82 128.63.4.82 26.3.0.29 |
| NIC.NORDU.NET | 192.36.148.17 |
Primary Master Name Server
The primary master name server (or primary) has authority over a zone. This server gets its authority from a parent name server, which could be a root name server or another primary master. You must register the primary master name server with its parent name server.
When the primary receives a query about a domain name, it first checks the domain to which the host in the query belongs. If the host belongs to the primary’s domain, the primary provides an authoritative answer. If the host belongs to another domain, the primary looks to its local cache for an answer from previous queries. This information is given a time-to-live (TTL) period, after which it becomes “stale” and is removed from cache. If the primary finds the information in cache, it returns a non-authoritative answer to the query.
If the primary doesn’t find the answer to the query in cache, it begins to query remote name servers. The primary continues to query these servers until it receives a valid answer or discovers that the host or its domain doesn't exist. A primary must have enough system resources to handle several queries simultaneously.
Secondary Master Name Server
When you use a primary master name server, a secondary master name server (or secondary) must be available as a backup. You must register the secondary with its primary so that the secondary is propagated as a “known” name server.
The secondary periodically verifies whether it needs to copy the database files from the primary in order to update its own database. In this way, the secondary contains the same current information as the primary. Verification is based on refresh interval and expiration times. Refresh intervals are when the secondary compares databases to find changes in the primary's database, and then propagates them if any are found. Upon expiration, the secondary has to get all new information from the primary.
Copying a database from a primary to a secondary is called a zone transfer. The secondary obtains its first copy of the primary server’s database files when you start your domain name services software. After that, periodic zone transfers keep the secondary server up to date.
The secondary must not have a common point of failure with the primary. This means that the primary and secondary cannot even share the same power supply.
The two masters are often distinct geographically. In fact, servers in different organizations often act as secondaries for each other.
When a secondary receives a query, it answers the query in the same way as the primary. The secondary first determines the requested host’s domain and compares it with its local database and cache. If it can't resolve the query locally, it sends out further queries.
Caching Name Servers
Caching name servers provide a caching function but aren't authorities for any zone or domain. Thus, you don't need to register them with their respective parents. Caching servers relieve the authoritative master name server of some of its burden.
Because the caching server isn't authoritative, it doesn’t maintain a database. When your domain name services software starts, the caching server loads a file with a list of root servers it can use to answer queries. It then maintains a local cache of information, again basing it on time-to-live expiration time and taking the appropriate action when the data expires.
Slave Name Servers
A slave name server can function like a primary, secondary, or caching server except that it doesn't try to contact another outside server. When it can't resolve a query locally or the query requires an authoritative answer, it forwards the query to one of several internally listed forwarders. Forwarders can be root, primary, secondary, or caching name servers.
Resolvers
A resolver is another name for a DNS client. A resolver communicates with a name server to resolve host names and internet addresses. The resolver doesn't maintain a database. It can only send queries; it can't answer them.
Some resolvers cache information for future queries, although non-caching stub resolvers are more common. Even with the “smarter” caching resolvers, most of the burden of finding an answer to a query resides with the name servers.
Queries
The local name server does most of the work when queried by a client. If the server can’t answer a query, it repeatedly acts on the referrals it gets from other name servers. This process eventually routes the query to the authoritative server closest to the target host. The local name server, in effect, “takes charge” of the querying process; the other name servers can't pass on referrals and the client resolver usually isn't sophisticated enough to act on them.
The resolver uses recursive querying. It requests that the local name server do the querying for it, and so on, recursively. However, the recursive process stops at the name server and starts to become iterative. The local name server stops passing the query. Instead, the local name server sends out iterative queries based on referrals from other name servers. After asking the same question over and over again of different servers deeper and deeper into the domain space, the local name server eventually gets the information it (and the resolver) needs.
Figure 1, shown previously in the book, is an example of an iterative querying process.
Older versions of applications, for example, nslookup, used another kind of query called an inverse query. Unfortunately, only the name server taking the inverse query can process such a query (it can’t forward it) and these queries take a long time to process. In most cases, reverse mapping — the next topic — will do the job just as well, if not better.
Domain Name-to-Address Mapping
Because DNS indexes data by domain name, it’s relatively easy to get the internet (IP) address of a host. However, it’s a bit harder to do a reverse mapping — finding a domain name based on an IP address. You’d have to do an exhaustive search through all the domain names. However, reverse mapping is often necessary since many TCP/IP applications like NFS look for host names instead of IP addresses (in .rhosts and hosts.equiv files, for example).
DNS resolves this by creating a special top level domain of reverse-order IP addresses by ending them with the IN-ADDR.ARPA. domain. It arranges the subdomains by each “decimal” octet in the 32-bit IP address, except in reverse order. Thus, IP address 192.42.95.122 becomes the reversely mapped address 122.95.42.192.IN-ADDR.ARPA. domain.